You are here
Spelling normalisation with VARD
June
20,
2015
On 19 June 2015 the LVTC team organised a seminar on corpus linguistics, in particular about the Variant Detector software (VARD). The seminar was run by Dr Alistair Baron, Faculty Research Fellow in the School of Computing and Communications at Lancaster University and a member of the prestigious research centre UCREL at Lancaster University, too.
Over the last 40-odd years, UCREL has developed crucial computational and corpus tools for the study of (mainly but not only) the English language, including present-day and historical corpora. As announced on their website, they “specialize in the automatic or computer-aided analysis” of corpora” and they “remain at the leading edge of computer corpus construction and analysis”. To name a few of these tools you may be familiar with: part-of-speech tagging with CLAWS, semantic tagging with USAS, grammatical parsing with ‘skeleton parsing’, and spelling normalisation with VARD.
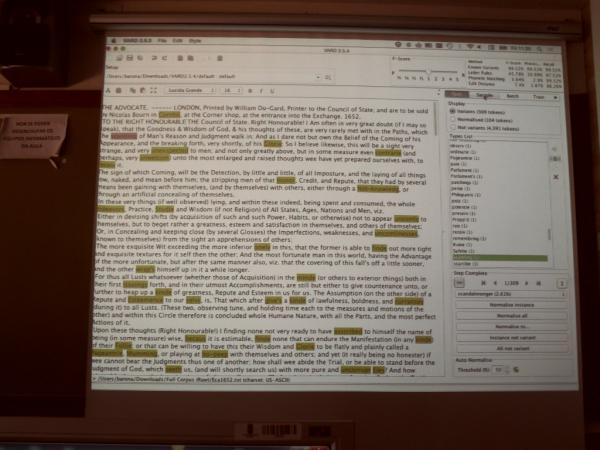
Dr Baron demonstrated how VARD acts successfully as a corpus pre-processor for text containing spelling variation, so that it first detects spelling variants and then finds candidates of modern equivalents. The added values of this tool are that (a) it allows users to keep both the original spelling and the normalised spelling side by side (with the possibility of hiding the latter in display view), and (b) it allows for manual intervention (including customised training) as well as automatic normalisation. A VARDed corpus will improve accuracy and precision of other corpus linguistics tools such as part-of-speech tagging and semantic tagging.
During the seminar Dr Baron took us through the various interfaces of this piece of software: the interactive mode for manual normalisation, the training mode for corpus customisation, and the batch mode for automatic normalisation. We were explained they key functionalities to get started such as the “setup” sidebar, the “rules” sidebar and the related DICER tool. Besides, we had the chance to have a hands-on session in which participants could explore the software with a corpus of their own interest.
The seminar was financially funded by the research group LVTC.